


In this article, we will talk about mutability, what it means, and the different trade-offs relevant to it when programming.
What is mutability?
A mutable value is one that can change during the execution of the program. It means that we can create a value, bind it to a variable, reassign the variable, or change parts of the value. We can see how it works in the following Javascript snippet:
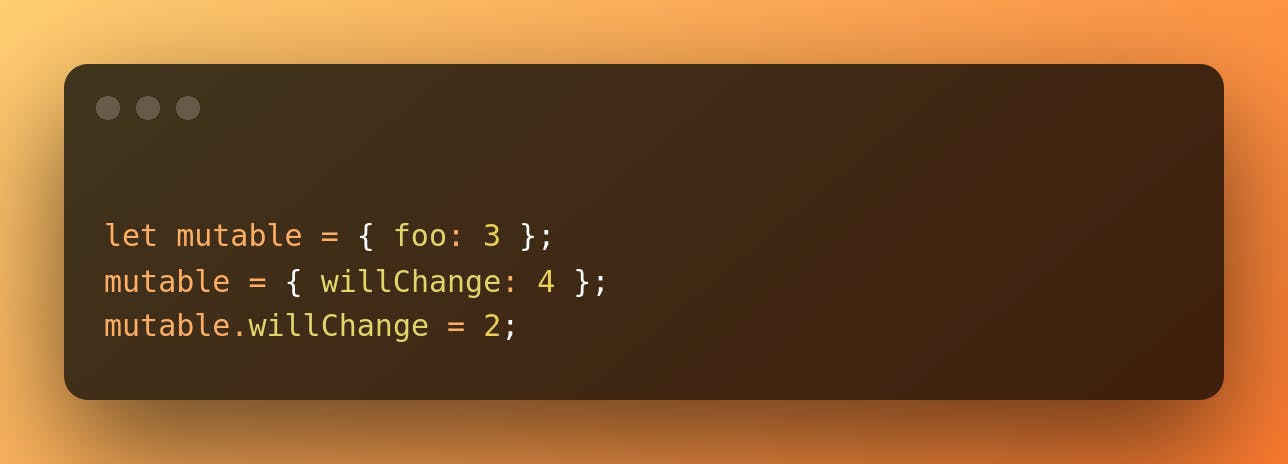
Notice that we talk about values and not variables because they are different. Having, in memory, an object that can change/be changed is a value. In contrast, having a mutable variable means that our access point to the value is mutable. In the snippet above, the variable is mutable, and some of the values are { foo: 3 }, { willChange: 4 }, and 2. In practice, mutability is handled by the compiler, so we'll be talking about both interchangeably most of the time.
On the other hand, we have immutability, which means the inability of a value/variable to be changed. Some examples of immutable values that we often find in programming languages are strings and dates. The reader might think: What use does a variable I cannot change have? Well, it may come as a surprise, but there are programming languages where everything is immutable.
Most of the time, we hear mutable this and immutable that, but no one takes the time to explain why we should understand the trade-offs. It is very relevant to know when to use mutable or immutable patterns since this can remove whole classes of bugs or make the code more readable and concise.
If one part of our code operates on the assumption that a value will never change and another part of our code changes that value, it's possible that the first part of the code won’t do what it was designed to do. The cause of this kind of bug can be difficult to track down after the fact, especially when the second piece of code changes the value only sometimes.
But first, let's see some ways we can encounter mutability in the wild.
Flavors of mutability
We can find mutability at the lowest level. In assembly languages, we interact with memory, mutating it the way we want without restrictions. It is relevant because we have to understand that mutation is a high-level concept. We don't talk about mutability at the assembly level: everything is mutable. The whole basis of computers is changing 0s to 1s.
At a higher level, there are programming languages where we cannot enforce immutability except in specific cases or built-in types. Python, for example, has no way of doing this; only if you use the immutable built-in types you get something close to immutable values. If we take a look at Python's tuples, we can see they are immutable, but with a catch:

It might be obvious to some, but we could argue whether it makes sense. Are tuples truly immutable?
Another example of this is Javascript const variables. There has been a lot of controversy around whether to use let or const, and we will not get into it. But one thing is clear: const does not mean immutability. At most, the name is immutable (more like read-only). We cannot reassign to a variable declared with const, but we can certainly mutate the values bound to that variable that have one level of indirection:
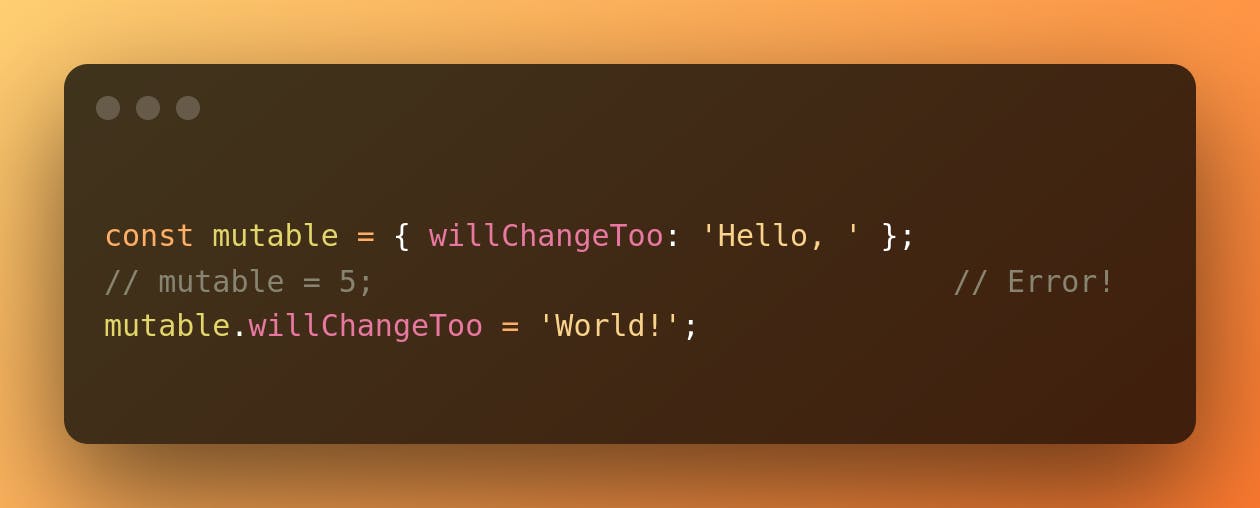
What we mean by indirection is that the reference is immutable, but the value that the reference points to is not. Are these variables truly immutable?
Other languages like C# and C++ have mutable values by default. However, there are programming constructs and techniques that enforce immutability. In C#, we can effectively implement custom immutable types, as shown elegantly in Eric Lippert's fabulous blog.
Other programming languages allow mutable and immutable variables like F# and Rust. Those two have immutable variables by default, and only after adding certain keywords is a variable effectively mutable. It is worth noting that mutability gets enforced by the compiler in the sense that it disallows operations of this kind:

The snippet above will not compile because the value is immutable, and we are trying to add an element to the vector (the value). In this case, the solution is to make the variable mutable with the mut keyword.

Finally, in languages like Haskell and Clojure, all values are immutable. That means that there is no way of mutating a value after creation.
We can find this concept at a higher level. Some libraries implement immutability as a first-class citizen.
Take ReactJS, for example. This paragraph merges the concept of pure functions with immutability, but we will try to stay in scope. ReactJS is a library for building user interfaces. The essence of it is that UI is a function of state. That sounds abstract, but it is good enough. The library maintains some state and renders the UI. We can say that render means paint to the browser, while the state is Javascript variables managed by the library. The relevant issue for us is that the state is immutable. To mutate the state, we use an updater function provided by the library, and we can only mutate the state by using this function to create new state. With this constraint, ReactJS guarantees to build the UI deterministically.
But still, the scale gets wider. We can talk about immutable infrastructure, an approach to deploying software where changes in place are not allowed. Instead, new deployments replace the old ones, making every deployment immutable.
Why do we care?
We now know at what levels we can find mutability, but why do we care? Well, being mutable changes the semantics of the program and has repercussions. See the following examples.
In the following code snippet, what is the value of whatAmI after calling sus?
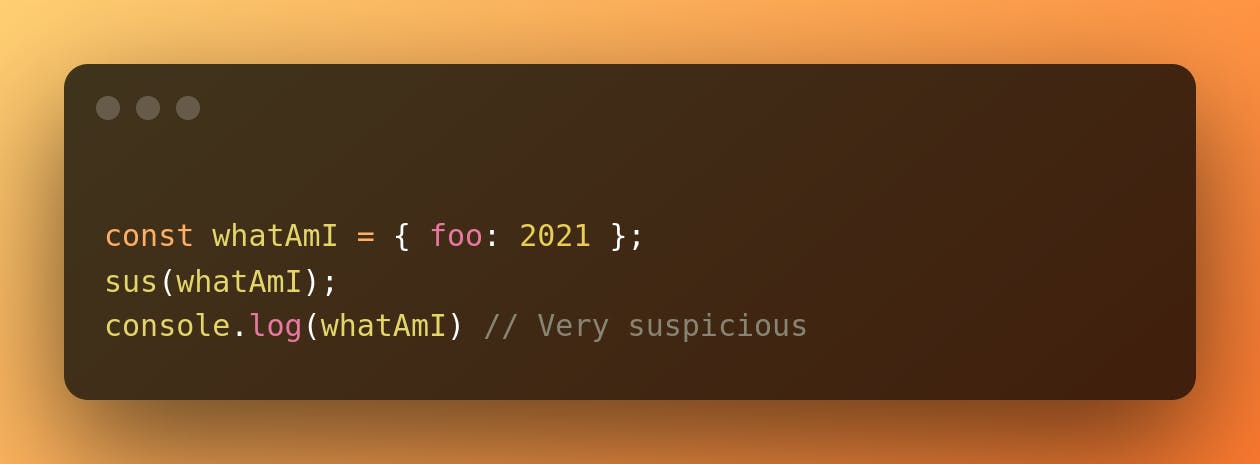
Well, it depends. We would have to check the code of sus to know the value of the variable. What if whatAmI was immutable? Then, we wouldn't care about the implementation of sus because we know that it just reads the variable. This is a good read for those who want to see more examples of how mutability can be worrisome.
On the other hand, look at the following comparison. We have the same semantics, first written with immutability in mind and then written while allowing mutation.
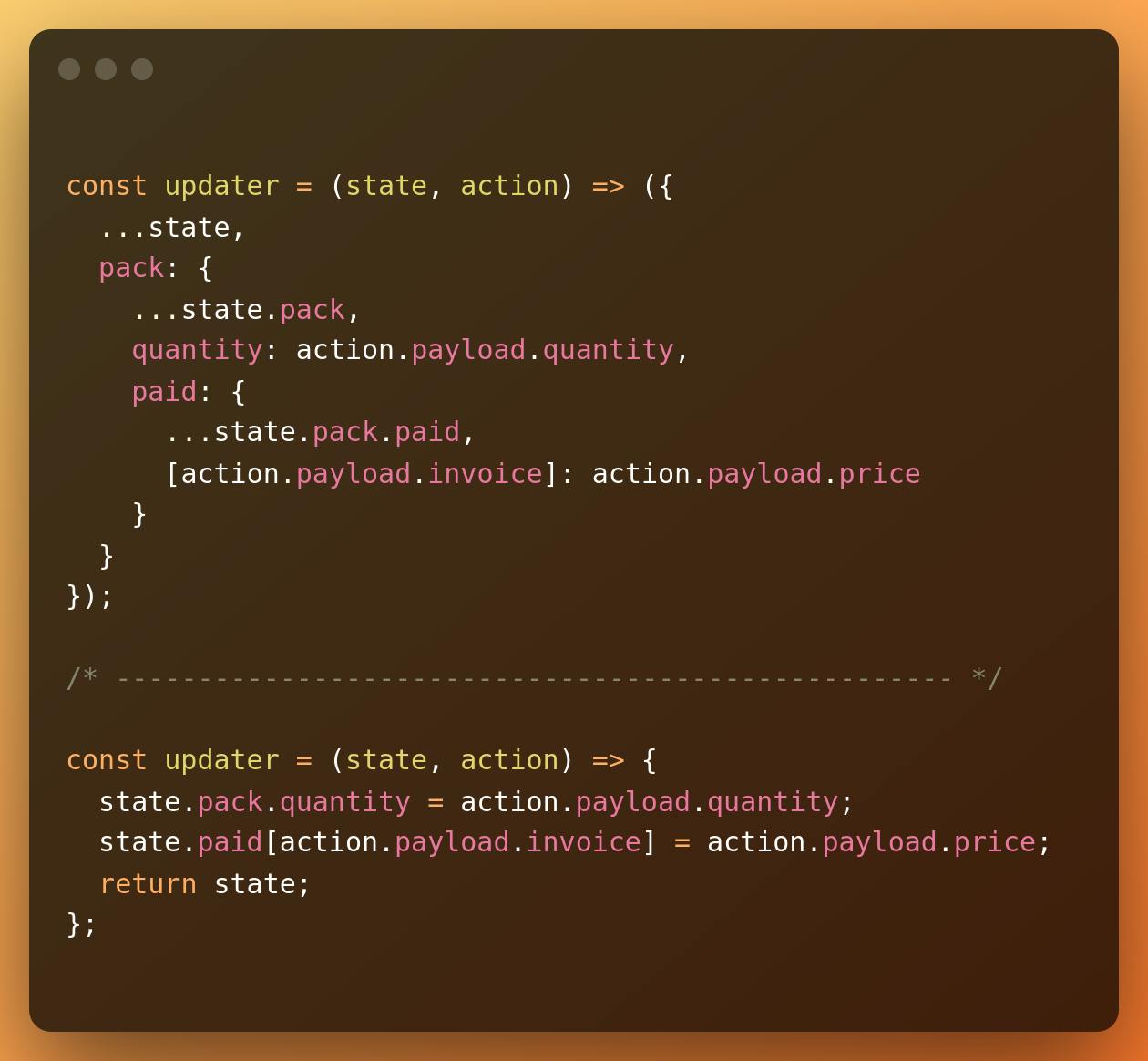
Writing update logic like this can be hard, and it is easy to miss a section because of a copy-paste error. Functional programming languages deal with this in various ways. However, using an imperative, mutable style when writing update logic might be the better way.
Immutability is a bit underused
Some of the perks of working with immutable values:
Often, immutability makes more sense. When we change the value
1or add a year to aDate, the values don't cease to exist. Instead, we have new values altogether.Making copies of immutable values is very cheap and fast. We can return the same value. Since it cannot change, every section of the program can refer to this particular value.
We can save memory with immutable values. If we had 100 instances of a string, they could all be changed to refer to that one value.
Immutable values are inherently thread-safe. Being unable to change removes the occurrence of data races.
Those are just a few, but you can see that immutability comes with several advantages. However, I think the trade-off is that immutable semantics are harder to write but easier to debug and reason about.
So why not combine the best of both worlds? It is what languages like Rust and F# do. Imagine enjoying the goodies about immutability while being able to opt-out when you want to. Is this the best scenario?